Introduction
A few moments to learn, a lifetime to master is an ancient proverb shouted to someone uninitiated in the game of Go. Also known as Baduk in Korean and Wei-qi in Chinese, Go is an ancient board game that means literally encircling game and as Edward Lasker, chess Grandmaster, stated, “the rules of Go are so elegant, organic, and rigorously logical that if intelligent life forms exist elsewhere in the universe, they certainly play go”.
The beauty of it comes from its apparent simplicity, two opponent in a 19 by 19 board have to fight with black and white stones for territory, capturing, threatening and isolating movements to assert control over more of the board than his opponent. The player who has more territory at the end game wins. Many people consider Go as a stylized representation of fighting a war, settling a frontier, cornering a market, thrashing out an argument, or even of fortune-telling and prophecy.
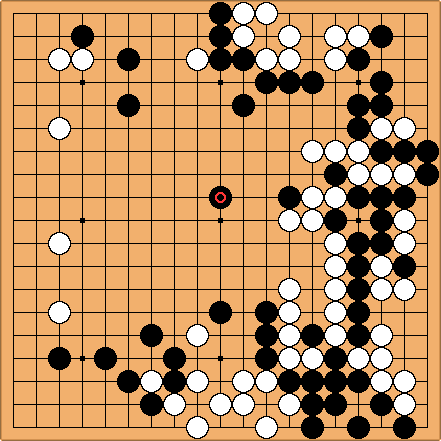
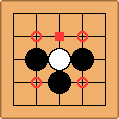
The game is played in a rectangular board as shown in the above Figure. Black and white stones have to be place in the intersected line. If the opponents stones surround a stone, the surrounded stone loses its liberty and it is said to be captured. During the game, players can connect stones to create groups and expand territory. A simple example of a stone being capture is shown in the Figure bellow.
The complexity of Go arises from players strategies. Professional players have memorized and studied an enormous amount of famous and well established joseki, which translate to the sequence of moves played. Usually, strategies changes and evolve during time. The many variation multitude of movements allows Go a vast number of diversity and variation of games.
In recent years the advance in computer programmers were able to create Go bots good enough to beat amateur level players. Essentially, Go bots have allocated in their memory enough joseki to be able to play in small board (9 by 9 or 13 by 13) games. Their main challenges consist of:
Number of spaces in the board. During the game, the number of legal moves stays around 150-250 per turn. When compared to Chess which average 37 moves per turn, it can be seen how exhaustive the computer program has to be to calculate the next move [@allis1994searching].
How the placement of stones interfere in the end game. Since the stones stay in place and never move, the computer program has to predict the influence of each move in the next hundred moves and repeat the calculations when the next stone is played.
At a glance a pro player can evaluate the territory count. For a computing program, there is no easy way to evaluate stones position.
These challenges have been the main reason Go computer programs have not succeed in the past. The traditional way of making a computer program had to change.
A different paradigm was used in AlphaGo to tackle the problem. AlphaGo utilizes a more direct approach in a sense that instead of using strict instruction it uses Deep Learning where the machine play itself millions of games so it can have a better understand of the game.
The objectives of this article is learn how AlphaGo works and its principles. Discuss why AlphaGo’s algorithm is successful comparing with older methods and create some conjectures about the future of AI and new challenges. This arcticle is strucutred as follow: first, the subject of artificial intelligence is introduce followed by a description of some concept used by AlphaGO. Next, AlphaGO architecture is discussed and some conjectures about AlphaGO future and AI are discussed. Finally, conclusion is made.
Artificial Intelligence
The general concept of Artificial Intelligence (AI) can be trace back to de decade of 1950 where pioneers dreamed about constructing complex machines who posses all human senses and intelligence. The current AI technology tries to emulate human cognitive capability using computational techniques and it can in fact execute specific tasks better than ourselves, although it still needs human intervention to implement, “train”, collect and provide external data. Computer program using AI methods are indeed data-driven that learn from input and output data presented to them. This is in opposition to physically-based models that use physical laws to derive underlying relationships in the system and require prior information and initial conditions.
In attempting to capture the relationship between the model input and output data, the AI modeling apply the same principles as statistical models. In a linear regression model, for instance, the unknown function $f$ that relates the input variable $x$ and the output variable $y$ can be found by minimizing the error between the actual output and the straight line. This same method can be apply to AI, in a sense that it uses available data to map the system input/output using machine learning through a iterative process (training). Successful methods have been created to tackle nonlinear problem such as Artificial neural networks (ANNs), Genetic algorithms (GA) and Evolutionary polynomial regression (EPR) and many others.
One of the key domains of current AI is the machine learning branching, more specifically reinforcement learning. the “learning” part of machine learning means that the algorithms attempt to optimize along a certain dimension, i.e. they try to minimize error or maximize likelihood of their predictions being true. The method consist of leaning from interactions. It maps situations to actions in order to maximize a numerical reward signal. In other words, the learner is not told which action to take, but instead it must discover which actions yield the most reward. Reinforcement learning has to store values for each state in order to select the best action that will maximize the reward in the long term. this task has shown to be too memory expensive and in some cases infeasible. For complex problems, an approximation techniques such as decision trees or neural networks are more suitable.
An overview of some of this concepts is given in the next following subsections.
Monte Carlo tree search (MCTS)
A tree search method normally work in depth first search. That means exploring all the way to the end branches of the tree before backtracking and evaluating the best path. Soon, people realize how this method was time consuming and memory intense for high branching factor.
Monte Carlo tree search is a variation of the normal tree search algorithm in a sense it scatter the order in which the tree is searched hence resulting is small branching factor. The premise of MCTS method is to analyze the most promising moves, expanding the search tree based on random sampling of the search space. For instance, a game is played many time by selecting moves at random. The final game results are weighted to select the best nodes that frequently resulted in victory, these nodes will be chosen in future plays. The basis MCTS consist of four steps: selection, expansion, simulation and backpropagation as indicated in Figure bellow
![MCTS algorithm with process break into four steps
[@chaslot2006monte]](/img/goarticle/mcts.png)
The first step, selection, works by selecting the optimal nodes until a leaf node whose statistics are unknown is reached. The next step, expansion, create multiple child nodes and through the simulation phase, select the one that get optimal results. The last step is the backpropagation which updates the current move sequence with the simulation result.
The search tree contains one node corresponding to each state $s$ that has been seen during simulations. Each node contains a total count for the state and an action value. Simulation starts from the root state and is divided in two stage. When state in represented in the search tree, a tree policy is used to select the corresponding action otherwise, a default policy is used to roll out simulations to completion. For the simplest version of the MCTS called greedy, it selects the action with high value in the first stage. In other words, the simulation phase consist of move randomly to the next branching state and keeping the statistics. Once many simulations have been completed, the algorithm can move to the best overall result and return the information to the previous nodes through backpropagation.
One of MCTS advantages is that it can be employed in games only with the game mechanics implemented in order to generate the search space. The tree search grows accordingly to the most promising subtrees, hence, it achieves better results than classical algorithm with high branching factor although it still has to run a large number of simulations in order to achieve good results. MCTS is useful for large state space even though it needs lots of samples to get good estimate. The planning phase is time independent of the number of states and running time is exponential in the horizon.
MCTS can use various heuristic from previous plays or experts players to influence the choice of moves. Certain patters of plays can increase the probability of moving in to a specific region. Techniques can be used to decrease time in the exploratory phase by employing rapid action value estimation (RAVE). Currently, some of the main Go programs use this method to achieve amateur levels of play. AlphaGO manages to go beyond that by using extensively the concepts of machine learning such as neural networks and at the same time avoiding using hand-crafted rules.
Neural networks (DNN)
Neural networks (NN) consist of many simple connected processors called neurons each producing real value activation. The neurons can interact with each other and with the environment triggering actions and collection data [@lecun2015deep], they also construct their policy and value networks. Since the meaning of the feature extraction procedure is difficult to understand, some early work uses embeds knowledge architecture into neural networks. In order to derive the corresponding learning algorithms and methods, NN uses fuzzy logic and genetic evolutionary computing. Fuzzy logic deals with truth values of variable that may be any real number between 0 and 1. This concept has been used to characterize the concept of partial truth, where the truth value may range from completely true to completely false. Evolutionary computation are algorithms inspired in biological evolution that mens they are based on population-based trial and error problem solvers.
The Figure bellow shows a diagram of a node trying to exemplify a neuron in a human brain. A neuron is where the computation happens, information is allocated and transmitted based on a series of factor and when it encounters sufficient stimulus. A neural network consist of many nodes transmitting information from one to another. Each node combines input from the data set with weights that either amplifies or decrease its importance based on what the algorithm are trying to learn. In other words, from an iterative process the weights are selected in order to minimize and error function. The next step in sum the input-weight products which go though a node called activation function that evaluate weather the signal affect the outcome.
![Diagram of a node that combines input data with a set of weights assign significance to inputs to produce the output
[@Deeplearning4j]](/img/goarticle/dnn.png)
Based on this concepts, NN rule consist of classification, association, deduction and generation. From an input vector $\textbf{x}$, the network classifies and generate $M$ patterns with $K$ decision rules through the deduction network. After, $N$ patters are designated as the input to the next stage and, finally, the output vector $\textbf{y}$ is created by the generation network. In order to implement the classification, association, deduction and generation network, a variety of method can be used such as convolution neural network (CNN), deep belief network (DBN), stack autoencoder (SAE) and recursive neural network (RNN). The nodes presented in the DNN can be interpreted as the following set of Fuzzy logic rules:
$$\begin{aligned} \text{Rule-r: If } x \text{ is } S_r, \text{ then } y \text{ is } U_r, \leq r \leq M \text{x} N\end{aligned}$$
where $S_r \subset {S_1,\dots,S_M}$ and $U_r \subset {U_1,\dots,U_N}$ are the input and output pattern in rule $\textbf{r}$, respectively.
the output of the neural network is obtained after a series of filtering operation.
Deep learning (DL)
Deep leaning refers to train a neural networks using many hidden layers. In recent publications, it has proven to be good when operating with big datasets and complex target functions. An algorithm is deep if the input parameter passes through many layers of nonlinearities before generating a output.
The lowest layer takes the raw data and by combining them with a random weight the data is send information up to the next layers. The information learned by this next layer is more abstract version of the raw data. The higher it goes up, the more abstract features it can be learned. Sometimes, the meaning of what is happening in the hidden layers is lost.
Deep learning, in other words, consist of training deep neural networks. The algorithms is divided in multiple levels of representations that form hierarchy concepts. Input parameters are then combined and weighted to the next layer. An algorithm can have as many layers as necessary before providing a output result and each layer uses data output from the previous layer forming a cascade of nonlinear processing units. DL can be based on unsupervised or supervised learning of multiples levels of data representation.
AlphaGo architecture
In this section, a discussion of AlphaGo architecture is made.
AlphaGo relies on two pillars to effective reduce the search space, position evaluation and policy networks. The first can reduce the depth of search by truncating the search tree as state $s$ and replacing the subtree below $s$ by an approximate value function that predict the outcome from state $s$. The second principle can reduce the breadth of the search by sampling action from policy $p(a \mid s)$ which is a probability distribution function over possible moves of $a$ in position $s$.
Go programs uses MCTS enhanced by policies trained to predict pro players moves. This approach can achieve only strong amateur play due to shallow policies and value function being based on linear combination of input features.
In order to increase performance, Alpha Go team proposed a combination of MCTS and deep convolution networks. The first component can be considered as a brute force approach and the second the learning component guiding the tree search procedure.
Convolution network is a type of neural network which restrict themselves to filtering operations. This method has proven to be well suited to image processing applications. It takes as input the current game state and represent it as an image.
The team passes to the board the positions as a 19 by 19 image using convolutional layers to construct a representation of the position. The neural networks are used to reduce the effective depth and breadth of the search tree by evaluating positions using the value network and sampling actions using the policy network.
AlphaGo trains in total three convolution networks, being two policy networks and one value network. The policy networks, based on the current game state, provide information and guidance concerning the action to be chosen in a form of a probability density function. The value network, on the other hand, gives an estimate value in form of a probability of the current state of the game. In other words, it predicts the likelihood of a win, based on the current board, similar to an evaluation function. The value network, at the beginning, has difficulties in predicting the game. As the game gets near the end, the value network tend to better perform.
In order to make the neural network as good as possible, it need to be trained. Its policy network were trained through an online Go server where player from different levels can play which provided an efficient way of learning with immediate feedback. More than 30 million positions from game play were analyzed and AlphaGo achieved an accuracy on a withheld test-set of $57\%$ which is remarkable rate of predictability of human moves. This method is called supervised learning and it was already done in previous Go programs.
The supervised network alternates between convolution layers with weights and rectifier nonlinearities. AlphaGO contains a total of 13 layers with a supervised training. A final softmax layer outputs a probability distribution over all legal moves as show in Figure bellow. The policy network from AlphaGo is trained on randomly selected pairs $(s,a)$ by applying gradient descent techniques.
![Schematic representation of the policy network
[@silver2016mastering]](/img/goarticle/polnet.png)
Another strategy used by the AlphaGo team and where the novelty lies is in the reinforcement learning policy network which consist of playing games between its own AI system. By doing that, it improved the policy networks and optimized the system to win and therefore improve itself. This strategy adjust the policy towards the goal of winning games instead of maximize the accuracy of predicting correct moves. Comparing the results, the reinforcement learning policy network won more than $80 \%$ of games against the supervised learning policy network. The team also tested against other Go program called Paichi which uses a sophisticated Monte Carlo approach and it is ranked a 2 amateur dan on KGS server. The reinforcement learning policy network won $85 \%$ of games against Paichi.
From previous attempts, the combination of two types of policies have proven to be more efficient than using only one type. The same can be said about the combination of MCTS and deep learning. A pure MCTS algorithm can not learn through experience. Each game is treated like the first one and it relies only in brute force and prior provided data.
The last stage of training consist of the position evaluation to estimate the value function that predicts the outcome from position $s$ of games played. Ideally, AlphaGo would like to predict the optimal value function under perfect play. But instead, it estimate the value function for its strongest policy using reinforcement learning policy network. The estimated value function is approximated using a value network with weights that are trained in a similar ways as the policy network. The difference is that the output is a single value prediction instead of a probability distribution.
Monte Carlo tree search in AlphaGo works by selecting in the tree the branching with maximum action value plus a bonus. The bonus value depends on prior probability stored in the edge. The leaf node can then be expanded and it can be processed by the policy network. Once each leaf node is evaluated by the value network and the rollout policy, new action values are updated and backpropagated
The AlphaGo team noticed that evaluating policy and value networks are more computational costly than traditional search heuristic. In order to efficiently combine MCTS with deep neural networks, the programs needs to use asynchronous multi-threaded search which executes simulations on CPUs and, in parallel, compute policy and value networks. According to the project, the final version of AlphaGo uses $40$ search threads, $48$ CPUs, and $8$ GPUs.
Conjectures about the future of AlphaGo and AI
In this section, my opinion and conjectures about the future of AI and AlphaGo are presented.
AlphaGo breaks a long and hard threshold that many people thought it would take longer than it did. Not only it showcase the new possibilities of AI, it made a lot of people interested in the subject. More people interested means more money and investments in research which will bring advancement to the field. Another point is that, the ideas utilized in AlphaGo are not completely new and are generic enough for the community to build similar model for other applications.
Although AlphaGo achievement are memorable, it can be seen the long road AI has to go before a true AI and functioning model of mind happens. Currently, we still live in an era of model of the word instead of model of mind.
Model mind can create systems capable of learning everything about the word. World model are the current status quo at any branch of science. The moment we accomplish a true model of the mind, word model will become obsolete. The mind model will create and maintain its own world model that can be changed through sensory inputs.
Many researches are moving away from human engineered features and human tuned classification functions. Consider the complexity of a navigation system, researches can take years crafting features and algorithms just to make a system navigate around a complex environment, but if an end-to-end learning model for a system navigation was to be developed, it would take just a few months for the machine to learn how to navigate around if sufficient data feed the algorithm.
An advantage lies in it general nature, since the algorithm does not need prior information as it will be trained for the needed task. A challenge facing Alpha Go team and many other in the machine learning researchers is create a algorithm that utilized unsupervised deep learning. Hence, the current deep learning can not be consider as true AI but it is going in the right direction.
the introduction of deep learning in AI brought some interesting new computer capability. With deep learning, as long as you have a large amount of data and computation power, the program can “learn” a good feature space from the data itself instead of build one. A good example of application of deep learn is in problems involving image and text content. Program that recognize and process text have been built in English language. If the program move into other language, it would not work since the solution was crafted with specific feature for English language only. This paradigm is change thanks to deep learning.
Companies, like Google, are collecting and using data from different languages into deep learning algorithms in order to learn new features and come up with text recognition to understand any language and image. In fact, many of Google own proprietary algorithm are being substitute by an equivalent and more efficient deep learning or other machine learning technique counterpart. The PageRank algorithm, for example, which was the initial key to their success is being replaced by a new algorithm called RankBrain based on deep learning.
Applications for deep learning and AI are starting to appear in other areas than games. Areas such as health care presents a big challenge for the researchers. Different from a game application that can be trained by playing itself and generate its own data, in health-care there is not a easy way to collect real meaningful data.
Some challenges can be found in Deep Learning, the so called adversarial examples. Since DL is relativelly new, most papers and the media prefer to concentrate in the good things, many do not like to hear about the failure cases of DL systems. However adversarial examples are a real threat to DL algorithms. Even the most advanced of deep learning algorithms such as Google DeepMind can easily be fooled by adversarial examples. These adversarial images are generated by well optimized perturbations (noise) that are barely perceptible yet to a DL system, the effect can be quite catastrophic. This can be very dangerous for self-driving car technology or other sensitive fields like medical diagnosis.
DL systems are also heavily supervised learning models requiring differentiable and soft objective functions, yet the $90\%$ or so of real AI-hard problems have non-differentiable and hard objective functions. Take for example, deep reinforcement learning (RL) is currently notoriously hard to train. DL systems also consume a lot of training data and are cumbersome non-gradual learning models, but they are currently the best we have now, but better algorithms, probably ensemble based are yet to be developed.
In the match between Lee Sedol and AlphaGo, there was moments where the AI played some unpredictable movements when analyzed by experts. No one could say, or rather decided not to, if it was a mistake or not. The movements were simply beyond human comprehension of the game. From the moment AlphaGo made some unpredictable move, Lee Sedol had already lost the match. This is a big paradigm humans will have to face when creating systems that can reach a level of intelligence that even we can not understand.
Many people think that the moment we create a true AI that can learn anything it wants is not far. Many say in the next 30 or 40 years we will enter a new era of Intelligent Technology (IT). The question if it will be an evil or good machine can be raised. For some skeptical people that will mean the end of humanity. For others, it will mean an opportunity to expand human knowledge, technologies and advancements. One thing is fro certain, the level of intelligence such a machine will have will surpass human level in a exponential manner that we could not even comprehend it the same way a ant can not comprehend our level of intelligence.
Conclusion
The main objective of this article was explain what is artificial intelligence and the concepts involved in creating the AlphaGo algorithm. An overview of concepts such as Monte Carlo tree search, reinforcement leaning, machine learning, neural networks and deep learning were given. Then an examination of AlphaGo architecture was given. Finally, a discussion about the future of AI and AlphaGo was made.
The biggest challenging of this article was to try contribute and enrich the topic and at the same time not deviate from what is written on the researched papers. The contributions come in the form of putting in the same paper important concept as well as some explanation and clarification of the many concepts in a easy way to understand. Also my opinions and conjectures from the many researched and media articles about the subject were given.
References
- S. Library. (2016) Rules of go - introductory. [Online]. Available: http://senseis.xmp.net/?BasicRulesOfGo 2.L. V. Allis et al., Searching for solutions in games and artificial intelligence. Ponsen & Looijen, 1994.
- D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. Van Den Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, M. Lanctot et al., Mastering the game of go with deep neural networks and tree search, Nature, vol. 529, no. 7587, pp. 484-–489, 2016.
- M. A. Shahin, State-of-the-art review of some artificial intelligenceapplications in pile foundations, Geoscience Frontiers, vol. 7, no. 1, pp. 33–44, 2016.
- R. S. Sutton and A. G. Barto, Reinforcement learning: An introduction. MIT press Cambridge, 1998, vol. 1, no. 1.
- G. Chaslot, J.-T. Saito, B. Bouzy, J. Uiterwijk, and H. J. Van Den Herik, Monte-carlo strategies for computer go, in Proceedings of the 18th BeNeLux Conference on Artificial Intelligence, Namur, Belgium, 2006, pp. 83–91.
- S. Gelly and D. Silver, Monte-carlo tree search and rapid action value estimation in computer go, Artificial Intelligence, vol. 175, no. 11, pp.1856–1875, 2011.
- Y. LeCun, Y. Bengio, and G. Hinton, Deep learning, Nature, vol. 521, no. 7553, pp. 436–444, 2015.
- Deeplearning4j. (2017) Introduction to deep neural networks. [Online]. Available: https://deeplearning4j.org/neuralnet-overview.html